Van bestand naar netwerk - de belofte van Records in Contexts (RiC)
Er is een moment in vrijwel elk digitaliseringsproject waarop alles ogenschijnlijk op zijn plaats valt. De scans zijn gemaakt, de bestanden netjes opgeslagen, de metadata ingevuld volgens de geldende standaard, en het geheel is, technisch gezien, duurzaam toegankelijk. En toch knaagt er iets.
Dat ongemak heeft te maken met een hardnekkige beperking van veel bestaande beschrijvingsstandaarden: ze beschrijven objecten, maar hebben moeite met het vangen van de wereld eromheen. Wie ooit heeft geprobeerd om complexe relaties tussen documenten en personen, instellingen en hun functies vast te leggen in EAD of Dublin Core, weet hoe snel die structuren beginnen te wringen.
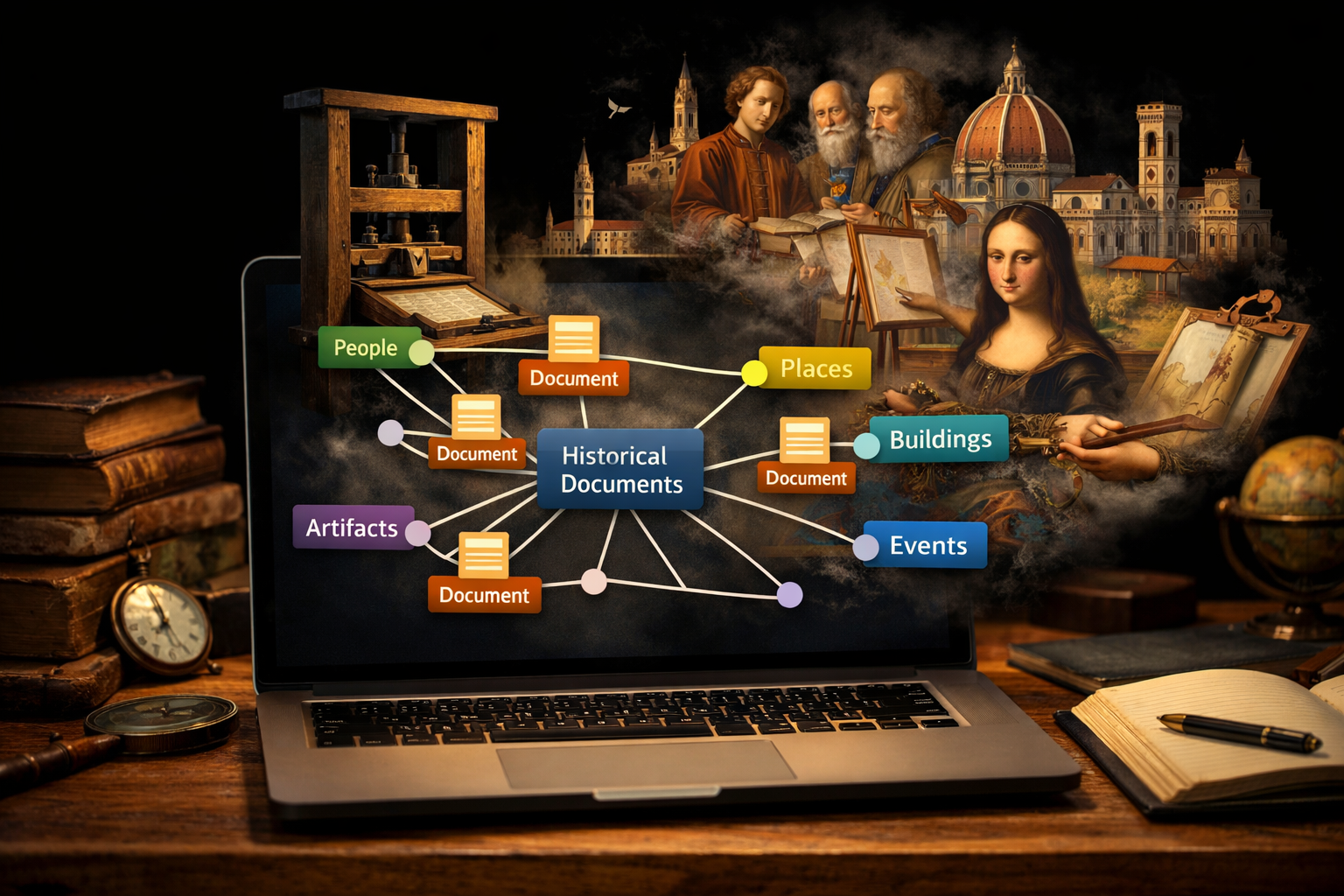
Met Records in Contexts (RiC) lijkt daar verandering in te komen. Niet omdat het nóg een standaard is die we moeten “implementeren”, maar omdat het een alternatief is en een andere manier van kijken introduceert. Voor RiC is niet het document het eindpunt van beschrijving, maar juist het begin, namelijk voor het opbouwen van een netwerk van entiteiten en relaties. Archiefstukken, personen, organisaties, functies en gebeurtenissen worden niet langer impliciet verondersteld, maar expliciet gemodelleerd en met elkaar verbonden. In die zin sluit RiC naadloos aan op een inzicht dat in de 'digital humanities' of digitale geesteswetenschappen al langer circuleert: betekenis ontstaat niet in het object zelf, maar in de relaties waarin het is ingebed.
Waar traditionele archiefbeschrijving sterk leunt op hiërarchische structuren (fonds > serie > dossier > stuk), biedt RiC een model waarin die hiërarchie slechts één van de mogelijke perspectieven is. Een archiefstuk kan tegelijkertijd: verbonden zijn met een maker (persoon of organisatie), voortkomen uit een specifieke activiteit, verwijzen naar andere stukken, en deel uitmaken van meerdere contexten. Dat is geen theoretische luxe, maar een praktische noodzaak. Zeker voor gebruikers die niet denken in archiefstructuren, maar in vragen als: wie, waar, wanneer, waarom.
Dit geldt ook voor digitale objecten. Een scan van een document is dan niet langer een eindpunt, maar een knooppunt: het verwijst naar andere documenten, naar degene die het schreef, naar de instelling die het voortbracht, naar de functie die het vervulde. In een goed gemodelleerde RiC-omgeving wordt een gebruiker als het ware door het archief geleid via relaties in plaats van via inventarisnummers. Bestanden komen daarmee, in zekere zin "tot leven".
Tegelijkertijd is er een probleem. Wie RiC voor het eerst bekijkt, ziet al snel de rijkdom maar ook de complexiteit. Het model is krachtig, maar niet eenvoudig toepasbaar. Voor veel instellingen voelt de stap van bestaande beschrijvingspraktijken naar een volledig relationeel model groot. De uitdaging is dan ook niet zozeer of RiC waardevol is, maar hoe we het werkbaar maken. Als RiC daadwerkelijk een rol wil spelen in de dagelijkse praktijk van archiefinstellingen, dan moet het ondersteund worden door 'tools' die aansluiten bij hoe archivarissen werken en denken. De vraag is daarbij niet alleen welke tool, maar ook welke strategie. Grofweg zijn er m.i. drie benaderingen denkbaar.
- Mapping tools (EAD / EAC-CPF > RiC). Deze bieden een logische eerste stap: bestaande beschrijvingen worden omgezet naar een relationeel model. Dat maakt impliciete verbanden zichtbaar en levert snel resultaat op. Maar mapping alleen is niet genoeg. De structuur van de brondata blijft doorwerken, en veel relaties blijven verborgen of incompleet.
- Specifieke RiC editors. Conceptueel zijn dit de meest zuivere oplossingen: archivarissen kunnen daarin direct werken met entiteiten en relaties. Maar de drempel daarvoor is hoog. Zonder aansluiting op de bestaande praktijk is de kans groot dat dit soort tools als te abstract wordt ervaren.
- Integratie in bestaande systemen. Het uitbreiden van bestaande collectie- of contentmanagementsystemen is pragmatisch en verlaagt de instapdrempel. Tegelijkertijd schuilt hier het risico dat RiC wordt "afgevlakt" tot iets dat lijkt op bestaande modellen en daarmee een deel van zijn kracht verliest.
Waarschijnlijk is geen van deze routes op zichzelf voldoende. Wat wél zou kunnen werken is een gefaseerde aanpak en hoogstwaarschijnlijk ligt de meeste kans van slagen in een combinatie van deze benaderingen: begin met mapping om bestaande data toegankelijk te maken in een RiC-structuur, voeg verrijkingstools toe om relaties expliciet te maken en uit te breiden, beweeg dus geleidelijk naar native RiC-verwerking voor nieuwe data en projecten. Wat voor tools zijn er dan écht nodig om dit te realiseren? Als je het terugbrengt tot de praktijk van alledag, dan zijn er m.i. vier typen tools die het verschil zouden kunnen maken:
- Visualisatie van relaties, Misschien wel de belangrijkste. Zolang relaties alleen bestaan als data, blijven die te abstract. Pas wanneer archivarissen en gebruikers netwerken kunnen zien en er binnen kunnen navigeren wordt de meerwaarde tastbaar (ik was zelf altijd zeer gecharmeerd van de AquaBrowser).
- Gebruiksvriendelijke relationele editors. Die bijvoorbeeld niet rechtstreeks werken met triples, maar met formulieren op basis van concepten als: “met wie hangt dit document samen?” en: “uit welke activiteit komt dit voort?”. Tools moeten relationeel denken ondersteunen zonder het technisch te maken.
- Semi-automatische verrijking. Om meters te kunnen maken, is ondersteuning nodig bij herkenning van personen en plaatsen, suggesties voor relaties en clustering van verwante objecten. De archivaris blijft beslissen, maar hoeft niet alles zelf bij elkaar te sprokkelen.
- Mapping als analyse-instrument. Mapping moet meer zijn dan conversie en moet antwoord kunnen geven op vragen als: waar ontbreken relaties? waar zitten inconsistenties? wat gaat verloren? Zo wordt mapping een manier om bestaande data beter te begrijpen.
Er zijn inmiddels tools beschikbaar voor conversie van bestaande standaarden naar RiC, en er bestaan al systemen die proberen het model daadwerkelijk als werkomgeving te implementeren. Daarnaast kan gebruik worden gemaakt van generieke linked data infrastructuur om RiC te modelleren en te publiceren. Maar juist rondom de tools die archivarissen in de dagelijkse praktijk gebruiken is het nog opvallend stil. Ze zijn nog slecht in staat om archivarissen daadwerkelijk te ondersteunen bij het incrementeel opbouwen en bewerken van relaties, die inzicht geven in netwerken van betekenis, of die de complexiteit van het RiC model vertalen naar een werkbare gebruikersinterface. In die zin bevindt RiC zich op een interessant kantelpunt. De conceptuele basis is gelegd, de eerste technische bouwstenen zijn aanwezig, maar de vertaalslag naar de praktijk moet nog grotendeels worden gemaakt.
Kortom: Records in Contexts is weliswaar een belofte, maar biedt geen snelle oplossing. Het vraagt om een verschuiving in werkwijze en tools: van enkel het beschrijven wat een object is, naar het tevens verduidelijken van hoe het verbonden is. Goede tools zullen daarin een beslissende rol spelen, zoals al vaker is gebleken bij het introduceren van nieuwe standaarden. Niet door de complexiteit van de standaard volledig zichtbaar te maken, maar juist door die complexiteit hanteerbaar te maken.
In het geval van RiC: door relaties te tonen, voor te stellen, en bewerkbaar te maken op een manier die aansluit bij de praktijk. Als dat lukt, verandert er iets fundamenteels. Dan wordt RiC niet alleen een model, maar een werkwijze. En dan worden digitale bestanden weer wat ze in wezen eigenlijk altijd al waren: knooppunten in een netwerk van betekenis.